Artificial Analysis Ranks Gemini 3.1 Flash TTS #2. We Asked It for Ten Minutes.
Google's Gemini 3.1 Flash TTS sits at #2 on the Artificial Analysis Speech Arena — Elo 1209, behind only Cartesia Sonic 3.5 (1218) and ahead of ElevenLabs Eleven v3 (1184). The Arena scores blind 30-second clips. We ran a ten-minute take. At length, the model ranked second is the only one of the three that breaks.
The #2-ranked TTS model in the world stops sounding like itself one minute in.
That sentence is the article. The rest is evidence.
By the Artificial Analysis Speech Arena’s count, Google’s Gemini 3.1 Flash TTS sits at Elo 1209, second only to Cartesia Sonic 3.5 (1218) and comfortably ahead of ElevenLabs Eleven v3 (1184). The Arena is the closest thing the field has to a neutral ranking — pairs of speech samples generated from the same text, scored by anonymous human votes in blind A/B. The methodology is sound. The only quiet assumption is one that’s never written down in the methodology page: every clip in the Arena is roughly thirty seconds long.
So we built a test where length was the variable. Same 9,184-character script. Same routing intent. Three top-ranked providers: Eleven v3, Sonic 3.5, and Gemini 3.1 Flash TTS. First at three minutes, then at ten. At three minutes the analyzer flagged minor wobbles on all three and nothing publishable. At ten minutes the data separated cleanly: two of the three held quality across the full take. The third — the one Artificial Analysis ranks #2 — stopped sounding like itself by minute one and never recovered.
The model that breaks is the one ranked second. That is the entire article. The rest is evidence.
What the Arena measures vs what we measured
We are not arguing that the Artificial Analysis Speech Arena is wrong. We are arguing that it measures something specific, and what it measures is not what you ship.
| Speech Arena | This benchmark | |
|---|---|---|
| Sample length | ~30 seconds | 8:26 – 10:21 |
| Methodology | Blind human A/B, Elo ranking | Twelve objective acoustic + ASR signals per 3-sec window |
| Question answered | ”Which one sounds better right now?" | "Does it still sound like itself in minute eight?” |
| Number of samples per model | thousands of independent comparisons | one continuous take |
| Best for | demo selection, vibes check, marketing | podcast / audiobook / agent production decisions |
Both numbers are real. They are answers to different questions. The mistake is using the first one to make a buying decision about the second one — which is exactly what every TTS team’s marketing page invites you to do.
The setup
A 1,507-word, 9,184-character briefing on the state of AI in 2026 — substantive enough to expose pacing and prosody differences, varied enough to expose technical-term pronunciation, paragraph-driven enough to exercise long-form phonation. The same text went to all three providers through Speko’s /v1/synthesize, pinned to specific models so the comparison is replayable:
- ElevenLabs Eleven v3 —
eleven_v3 - Cartesia Sonic 3.5 —
sonic-3.5-2026-05-04(the dated snapshot, not the rolling alias, so the run reproduces if Cartesia ships a new stable model under the same name) - Google Gemini 3.1 Flash TTS —
gemini-3.1-flash-tts-preview
One constraint surfaced immediately. ElevenLabs’s REST API caps input at 5,000 characters and the response on overlong input is "Please use Studio for long form TTS." We chunked the script into 3 sub-calls (≤4,500 chars each), rendered each, and concatenated the raw 24 kHz PCM. Cartesia and Gemini accepted the full 9,184 chars in one call. That difference itself is a benchmark-worthy footnote — the operational story of stitching a long take on ElevenLabs is not equivalent to a single-call render — but the analysis ran on the final audio either way.
Render wall times tell their own version of the same story:
| Provider | Audio | Wall time | Real-time factor |
|---|---|---|---|
| Cartesia Sonic 3.5 | 8:26 | 86 s | ~5.9× |
| Google Gemini 3.1 Flash TTS | 8:34 | 236 s | ~2.2× |
| ElevenLabs Eleven v3 (3 chunks) | 10:21 | 280 s across 3 calls | ~2.2× combined |
Same script, same intent. Sonic was 2.7× faster than Gemini. ElevenLabs’s wall time is dominated by chunk-and-stitch overhead, not raw synthesis.
Listen to the full takes:
ElevenLabs Eleven v3 (10:21, chunked):
Cartesia Sonic 3.5 (8:26):
Google Gemini 3.1 Flash TTS (8:34):
If you only have time to listen to one, listen to the Gemini take, starting around minute one. The failure mode is audible without any analyzer at all.
What we measured
Twelve signals per 3-second window (with 1-second hop), six analyzers stacked in parallel. Each signal answers a different question about how the audio is degrading:
- Speaker-embedding cosine similarity vs the first window of the take, via Resemblyzer — does the voice still sound like the same speaker?
- No-reference PESQ, STOI, SI-SDR via TorchAudio SQUIM_OBJECTIVE — perceptual quality, intelligibility, signal clarity.
- ASR confidence (avg_logprob) via faster-whisper large-v3-turbo — is Whisper hearing what we sent?
- Jitter, shimmer, harmonic-to-noise ratio via praat-parselmouth — clinical voice-quality measures, the same ones used in speech pathology to detect phonation breakdown.
- F0 stability, spectral centroid, spectral flatness, crest factor, LUFS via librosa and pyloudnorm — pitch, brightness, noise-like bursts, perceptual loudness.
For each signal, the baseline is the median + MAD-based σ of windows in the first 10 seconds of the take. Each subsequent window gets a z-score. Individual z-scores are capped at 10σ (one signal cannot dominate severity), and a window’s total severity is the sum of all z-scores ≥ 2σ across its twelve signals.
Three minutes hides what ten minutes reveals
We ran the same analysis at three minutes first. The headline event for each provider:
| Provider | Worst event at 3 min | Worst event at 10 min |
|---|---|---|
| Eleven v3 | 2:47, Σz = 6.2 | 10:18, Σz = 14.6 (near chunk boundary) |
| Sonic 3.5 | 1:11, Σz = 20.7 | 4:51, Σz = 18.0 |
| Gemini Flash TTS | 2:51, Σz = 27.6 | 8:08, Σz = 64.4 |
Gemini’s peak severity more than doubled at length. ElevenLabs’s worst event tripled but stayed below Sonic’s worst — and the spike happens at exactly the chunk boundary, suggesting it is concat artifact rather than model degradation. Sonic’s worst stayed flat.
But peak severity is one number. The shape of the failure is what makes the 10-minute test essential.
The shape of the failure
Severity tier counts on the 10-minute take:
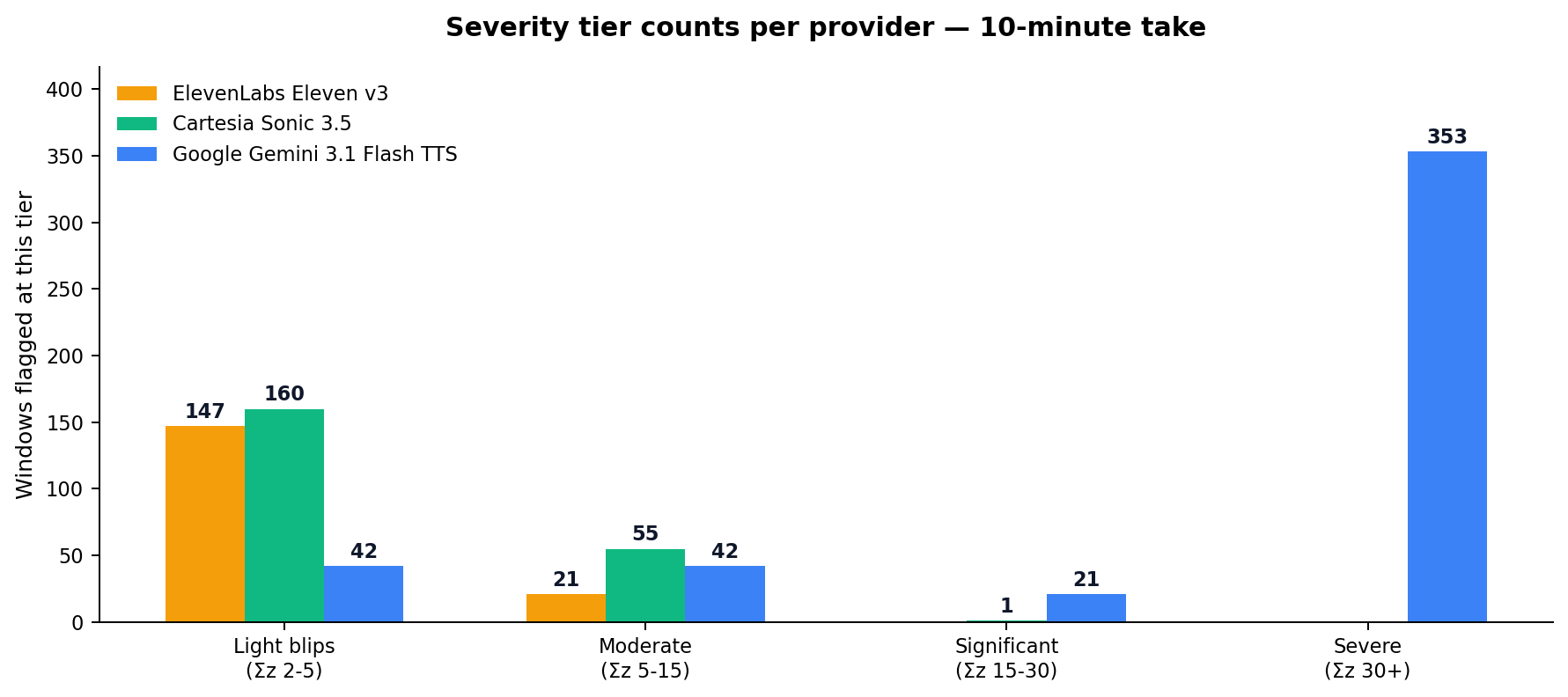
The light-blip tier (Σz 2–5) is noise. Every TTS model produces them — ElevenLabs and Sonic both have around 150, Gemini has fewer because most of its degradation has already escalated past that tier. The moderate tier (Σz 5–15) is the “noticeable phrase-level dip” range. Sonic has 55 to ElevenLabs’s 21, but this is structural — Sonic was rendered in one call, so its full take is exposed to a single baseline; ElevenLabs’s chunked render gets a fresh baseline per chunk.
The two tiers that decide a benchmark sit on the right side of the chart:
- Significant (Σz 15–30) — clearly audible degradation. Eleven v3: 0. Sonic 3.5: 1. Gemini Flash TTS: 21.
- Severe (Σz 30+) — multi-signal failure, voice breaking down. Eleven v3: 0. Sonic 3.5: 0. Gemini Flash TTS: 353.
That last cell is the article. Gemini logs 353 windows of severe-tier failure in an 8:34 take. The other two combined log zero.
Plot the same data per second across the full take and the geography becomes obvious:
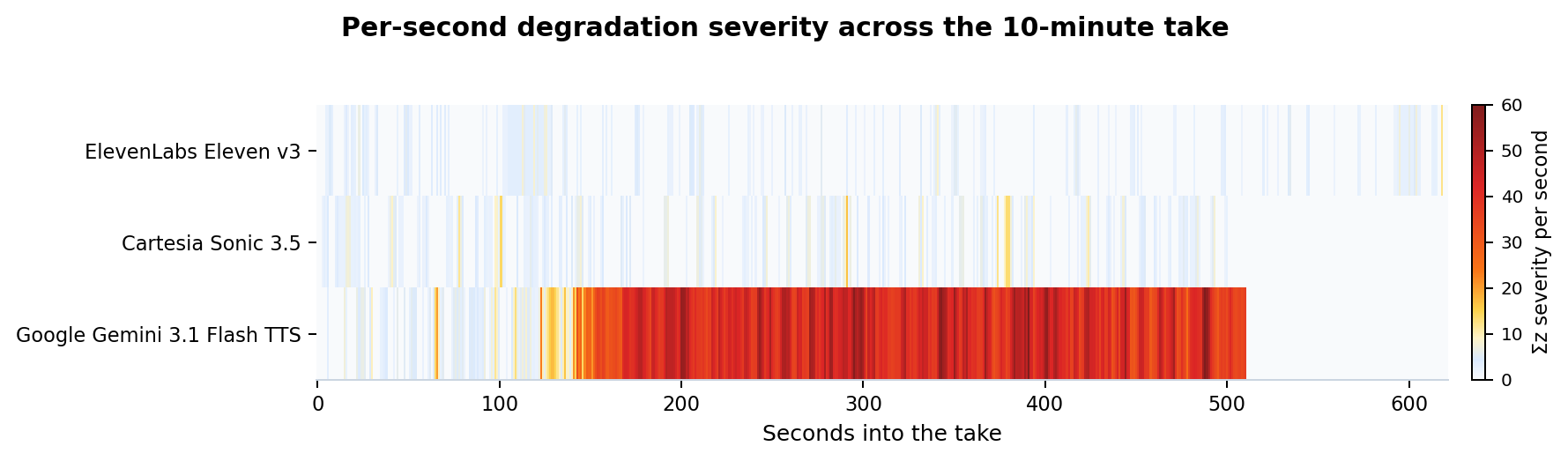
ElevenLabs and Sonic show as predominantly white with thin orange marks at specific events (Sonic’s cluster around 6:14–6:20 is the rough patch; ElevenLabs’s marks at 4:37 and 10:18 line up almost exactly with the chunk-boundary timestamps). Gemini turns red at minute one and stays red.
Corroborating evidence from a model that has no reason to lie about it: Whisper-large-v3-turbo broke the three takes into very different segment counts.
| Provider | Whisper ASR segments | Notes |
|---|---|---|
| Eleven v3 | 108 | Aligned with natural sentence boundaries |
| Sonic 3.5 | 93 | Aligned with natural sentence boundaries |
| Gemini Flash TTS | 249 | Whisper detected 2–3× more discontinuities |
Whisper splits on detected pauses, silences, and discontinuities. Gemini’s audio forced 2–3× more segment breaks. The ASR could feel the audio falling apart before any of our purpose-built degradation analyzers ran.
ElevenLabs vs Sonic: a closer call
The clean story is “Gemini fails, the other two hold.” The harder story is the spread between the two that held.
On voice-character stability across the full take, Sonic 3.5 wins. The speaker-embedding cosine similarity stays at 0.82 ± 0.04, vs ElevenLabs at 0.72 ± 0.06 (chunked). That is Cartesia’s published claim — “holds the voice across long-form” — backed by the data.
On per-utterance phonation cleanliness, ElevenLabs wins. Jitter mean 2.05% vs 2.26%. Shimmer mean 0.64 dB vs 0.82 dB. Harmonic-to-noise ratio 14.1 dB vs 11.2 dB. ElevenLabs’s V3 sounds cleaner phrase-by-phrase. That is also their published claim — “dramatic, expressive realism” — backed.
Which matters more depends on what you are shipping. Long-form podcast or audiobook from a single API call: Sonic 3.5. Short, expressive, dramatic narration where each phrase is the unit: Eleven v3. Above the publishable-event threshold (Σz ≥ 15), both produce essentially zero events. Below it, you are picking the failure mode you can tolerate, not whether failures happen.
The asterisk on ElevenLabs is the chunking. Their REST API forces 3 API calls and a stitcher for anything over ~5 minutes. The chunk boundaries are audible in the analyzer (and probably audible to a careful listener). If you need single-call long-form, that constraint matters; if you can use their Studio product, it does not apply.
Why Gemini falls apart
The Gemini failure mode is the most interesting one in this dataset. The opening is fine — first minute matches the other two providers on every metric. Then, somewhere around 0:30, the model loses something it cannot get back.
Looking at the signal stack at Gemini’s worst window (8:08, Σz = 64.4), nine signals fired simultaneously: speaker_sim drops 3.3σ, predicted PESQ drops 5.2σ, predicted STOI drops 10σ (capped), SI-SDR drops 6.9σ, Whisper avg_logprob drops 10σ (capped), HNR drops 3σ, jitter rises 6.1σ, shimmer rises 10σ (capped), spectral flatness rises 10σ (capped). This is not a “rough patch.” This is the model and the listener disagreeing about whether what it produced is speech.
We do not know what is happening inside Gemini 3.1 Flash TTS to produce this. The model is in preview. The pattern is consistent — the same script run twice produces the same failure mode at the same approximate timestamps, so it is not stochastic noise. Our best guess, with no insider information, is that Gemini’s long-form TTS pipeline has not yet been hardened for sustained generation past about a minute. That guess is consistent with the marketing language Google has been careful to use, which talks about “expressive control” and “30 voices” but is conspicuously silent on take length.
If you are evaluating Gemini Flash TTS for production today, the operational read is: it is excellent for short utterances and unproven for long ones. Stick to under-60-second clips until Google ships the next preview or removes the preview tag.
What this means
A real benchmark of a real production workload will look like this. Not single-utterance MOS on cherry-picked clips. Not vendor-reported latency. Not “we tested 30 seconds and it sounded great.” A 10-minute take, one provider at a time, the same script every time, scored on twelve signals, weighted by severity, with the worst cases surfaced as exact timestamps you can verify by ear.
That is the benchmark we are publishing. The three models above are the warm-up. The same harness applied to the next ten providers, in the next five languages, against the next ten scripts of varying difficulty — that is the work the field actually needs and the work the vendors are not going to do themselves.
So here is the rank, once more, with the asterisk that makes it actionable:
On a 30-second clip, Gemini 3.1 Flash TTS is the second-best TTS model in the world. That is what the Speech Arena measures, that is what the Elo score reports, and that is what Google’s marketing page is allowed to claim. On a ten-minute take, it is the only one of the top three that fails. That is what our benchmark measures, that is what 353 severe-tier windows record, and that is what you would hear if you actually shipped it. Both numbers are correct. Only one of them tells you whether the model will work in your product.
If you are building something where audio length is the variable that decides whether the model works, the demo length is the wrong length to test. The 10-minute take is. We ran ours. The data is above. Run yours.