How Anglicized Is Your TTS? Measuring Phonological Authenticity Across 7 Providers
The anglicization index measures how often a TTS model substitutes a target-language phoneme with its nearest English neighbor. We applied it to 7 providers across 4 Southeast Asian languages and surface the per-language rankings, the largest spread we measured, and what the numbers sound like.
Play these two clips. Both are reading the same Filipino passage. The words are identical. The phonetics are not.
Inworld TTS 2 (anglicization 0.926):
xAI TTS (anglicization 0.792):
Two readings of the same Filipino prompt. The xAI take sits closer to Filipino phonology — softer glottal handling, less aspirated stops, vowel quality that leans toward Tagalog’s tense-mid set. The Inworld take leans more American — fluent and articulate, with English-shaped consonants and vowels reading Filipino orthography.
This post is about the number that quantifies the difference between those two clips, what we measured across 7 providers and 4 Southeast Asian languages, and where the per-language rankings land.
The metric
The anglicization index is what your ear is registering, made into a number. Allosaurus — a universal phoneme recognizer — reads the audio and outputs IPA symbols for whatever sounds appear, regardless of language. We then ask:
For phones that exist in the target language but don’t exist in English (the “marked” phones), how often does the model produce the actual phone vs. substitute its nearest English neighbor?
- Score 0 = native phonology. Every marked phone produced as itself.
- Score 1 = pure English phonology. Every marked phone substituted.
- Score in between = partial production. Some phones land natively, others don’t.
The index is computed from waveform alone. No human raters. No vendor metadata. Same Allosaurus model on the same audio produces the same number.
The per-language picture
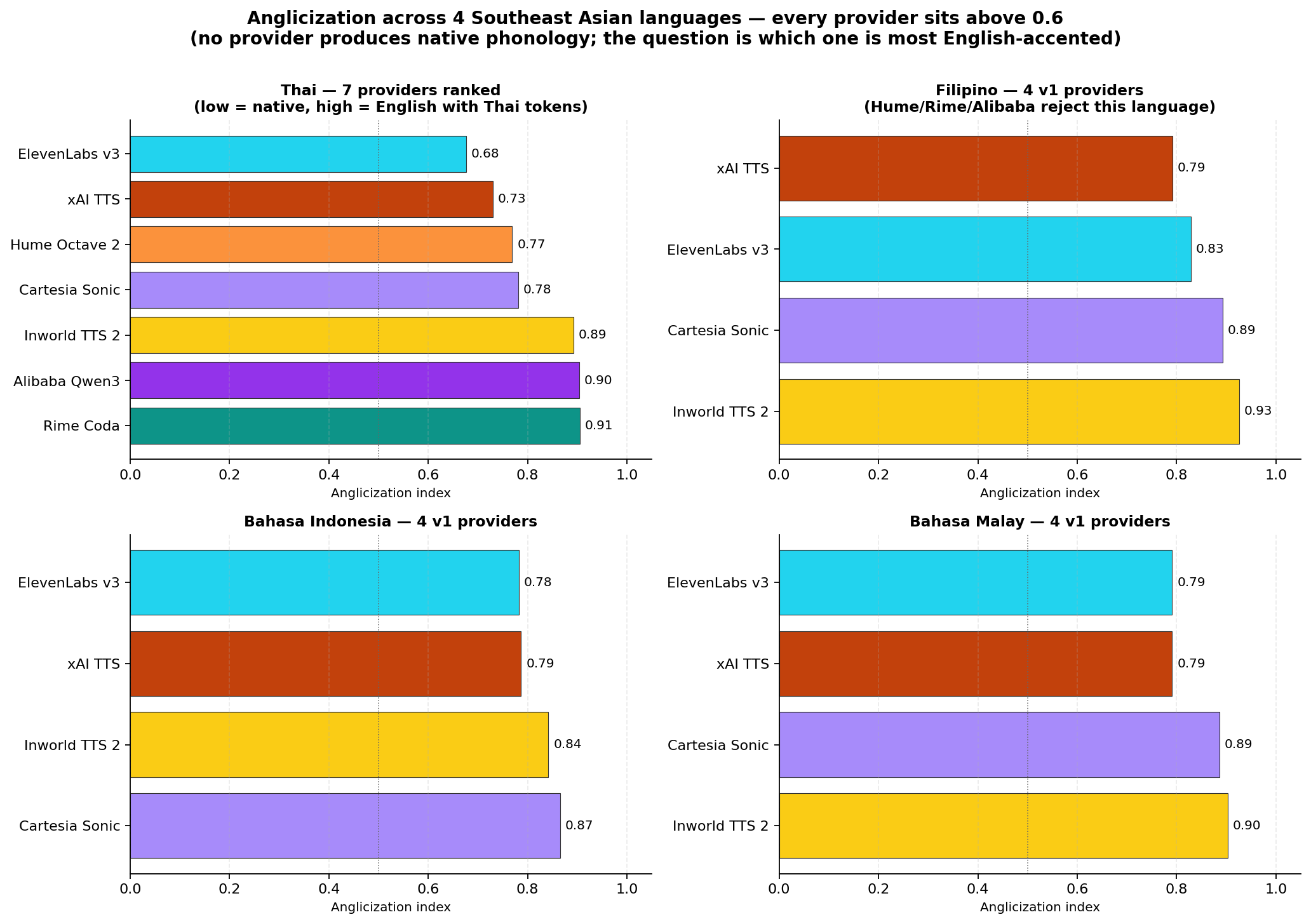
The lowest score in the benchmark is ElevenLabs v3 at 0.676 for Thai. The highest is Inworld TTS 2 at 0.926 for Filipino. Every score in between corresponds to a measurable degree of phoneme substitution — the higher the number, the more often the model reaches for an English neighbor.
The provider ranking changes per language:
| Language | Best (lowest) | Worst (highest) | Spread |
|---|---|---|---|
| Thai (n=7) | ElevenLabs v3 — 0.676 | Rime Coda — 0.905 | 0.23 |
| Filipino (n=4) | xAI TTS — 0.792 | Inworld TTS 2 — 0.926 | 0.13 |
| Bahasa Indonesia (n=4) | ElevenLabs v3 — 0.782 | Cartesia Sonic — 0.866 | 0.08 |
| Bahasa Malay (n=4) | ElevenLabs v3 / xAI — 0.791 | Inworld TTS 2 — 0.903 | 0.11 |
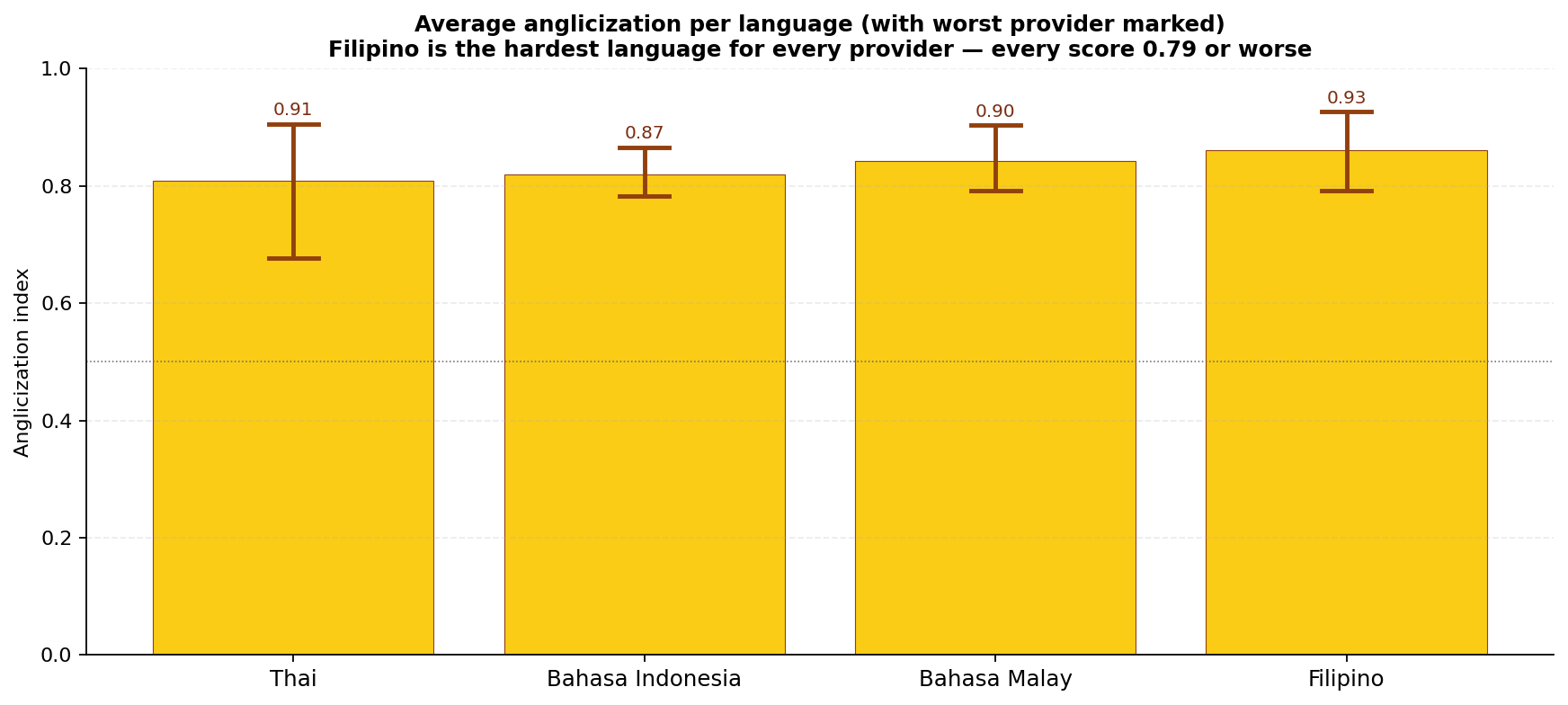
Filipino sits in the tightest band: every provider tested scores in the 0.79–0.93 range. Indonesian and Malay show wider spreads (0.78–0.87 and 0.79–0.90). Thai has the widest spread of any language tested at 0.68–0.91 — interesting because that’s also the language with the largest test set (7 providers).
Hear the highest-scoring provider per language
Thai — Inworld TTS 2 (0.892, highest of the original 4)
(Rime Coda scores 0.91 but renders only short prompts — a syllable sample is in the assets folder if you want it.)
Filipino — Inworld TTS 2 (0.926, highest in the benchmark)
Bahasa Indonesia — Cartesia Sonic 3.5 (0.866)
Bahasa Malay — Inworld TTS 2 (0.903)
Hear the lowest-scoring provider per language
These are the providers with the lowest anglicization index in each language. The numbers still sit in the 0.68–0.79 range; a native speaker is the best judge of how the audio actually lands.
Thai — ElevenLabs v3 (0.676)
Filipino — xAI TTS (0.792)
Bahasa Indonesia — ElevenLabs v3 (0.782)
Bahasa Malay — ElevenLabs v3 (0.791)
Why the numbers sit where they do
Modern multilingual TTS models share a structural choice: English-pretrained backbone, multilingual post-training. The base model learns the phoneme-to-waveform mapping on English data (massive corpora, hundreds of speakers, decades of recordings). Post-training adds target-language vocabulary, prosody, stress patterns — but doesn’t retrain the acoustic foundation.
So when the model encounters a marked phone — a Thai aspirated retroflex, a Filipino glottal stop, an Indonesian tense mid-vowel — it doesn’t refuse. It picks the closest English sound by feature distance and ships that. The target language’s orthography drives word selection; the English-trained acoustic model produces every actual sample.
This isn’t a bug, it’s the architecture. Fixing it requires either:
- Training the acoustic model on substantial native data in the target language (expensive, not yet done at scale for most SE Asian languages)
- Separating phonological generation from waveform synthesis with a per-language acoustic head (architectural reach, more compute)
- Hand-curating a per-language phoneme inventory for the model to draw from (Cartesia and ElevenLabs do some of this for their flagship languages; clearly not for Filipino/Thai/ID/MS)
Until one of those happens, “100+ languages supported” reasonably translates to “we accept 100+ BCP-47 tags; how natively any specific language sounds depends entirely on training-data investment per tag.”
What buyers should do
-
Don’t rely on the vendor’s supported-languages list. It tells you the model won’t 4xx. It doesn’t tell you whether a native speaker will accept the output.
-
Pick the best-of-bad for your target language. Looking at the table above, ElevenLabs v3 is the consistent leader for Thai/Indonesian/Malay anglicization; xAI is best for Filipino. Inworld is the most-anglicized in three of four languages — interesting given Inworld lists most of these as “experimental” in its docs (only 15 languages are GA).
-
Bring a native speaker to your evaluation. The anglicization index correlates with foreign-accent perception, but it’s not a substitute for a Filipino dev listening to a Filipino clip and saying “this is fine” or “this is American.”
-
Budget for either localization or expectation-setting in your product. If you’re shipping a voice agent to a Tagalog-speaking market and your product positions itself as “AI that speaks your language” — your users will hear an American. Either fund the localization gap or position the product as “AI assistance available in your language” rather than “AI that sounds like you.”
What this is not
The anglicization index measures one specific thing — how much of a target language’s distinctive phoneme inventory survives in the rendered audio. It does not measure overall TTS quality. Inworld has the flattest jitter and best Thai tone fidelity of the original v1 set; Cartesia leads on short-form latency; ElevenLabs has the broadest prosodic vocabulary. Each provider has the features its training data and architectural choices invest in. The anglicization finding is narrower than the providers themselves.