The Cartesia Drift: 10% of Voices Hold the Line for a Minute. The Other 90% Don't.
Cartesia Sonic 3.5 ships 378 English voices. We sampled 50 and ran a long-form drift probe. Only 5 of them stay above the perceptual same-speaker threshold at 60 seconds. The default voice Speko gateway pins is not one of them.
Listen to the first ten seconds of this clip, then skip to the last ten seconds.
That is the same generation, from the same provider, from the same voice ID, of the same text. It is not the same speaker by the end.
The provider is Cartesia Sonic 3.5 — currently ranked #1 on the Artificial Analysis Speech Arena. The Arena scores blind 30-second clips, and on that test Cartesia is the best in the world. Run the same model for two minutes and what you ship can be a different speaker.
But what makes this story interesting isn’t that “Cartesia drifts.” The story is that whether Cartesia drifts depends on which voice in their catalog you picked. Some voices stay rock-stable for eight minutes. Others fall apart in ninety seconds. Same underlying model. Different stability profile.
The number
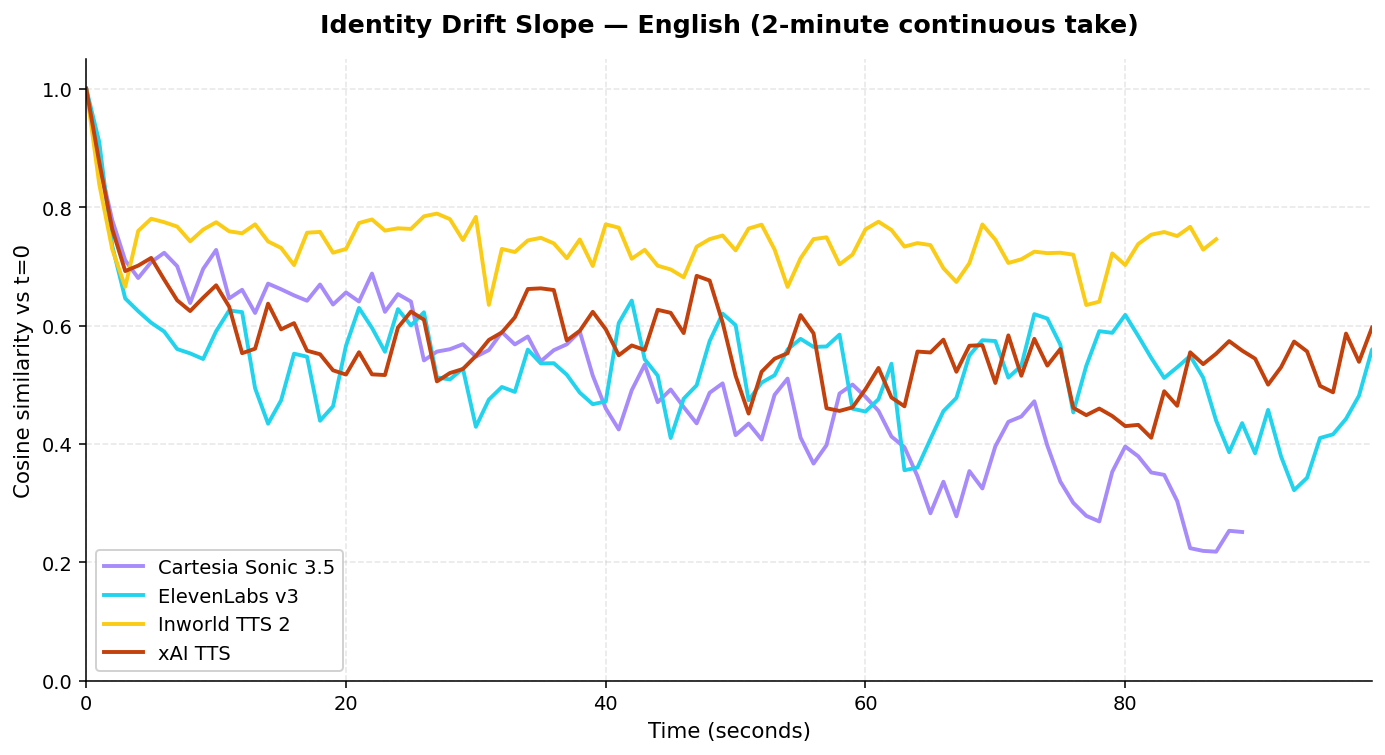
Twenty-five times we asked Cartesia Sonic 3.5 (and three other top-tier providers) to read the same two-minute English monologue, using each provider’s default voice. Then we ran a sliding speaker-embedding window across each take and fit a linear regression to the cosine similarity between each window and the start of the audio. The slope of that line is β — units of cosine similarity / minute. Closer to zero is better; negative means the voice is drifting away from itself.
| Provider | β (cosine / min) | σ across 5 takes | R² |
|---|---|---|---|
| Cartesia Sonic 3.5 (default voice) | −0.30 | 0.043 | 0.86 |
| ElevenLabs eleven_v3 | −0.07 | 0.033 | 0.21 |
| xAI tts | −0.08 | 0.019 | 0.19 |
| Inworld TTS 2 | −0.04 | 0.004 | 0.08 |
On the default voice, Cartesia’s slope is roughly four times steeper than the next provider. The R² of 0.86 says the trend is genuinely linear — it is not noise around a stable mean. The σ of 0.04 across five independent takes says the drift is not a one-off.
For comparison, here is the same monologue from Inworld TTS 2, the most stable provider in our lineup:
Inworld stays recognizably the same voice from start to finish. Cartesia’s default voice does not.
The voice catalog matters more than the model
A reader pointed out the inconvenient fact: a separate 8-minute Cartesia take we published two days ago sounded completely stable end-to-end. Same model. Same Sonic 3.5. Why doesn’t that audio drift the way these takes do?
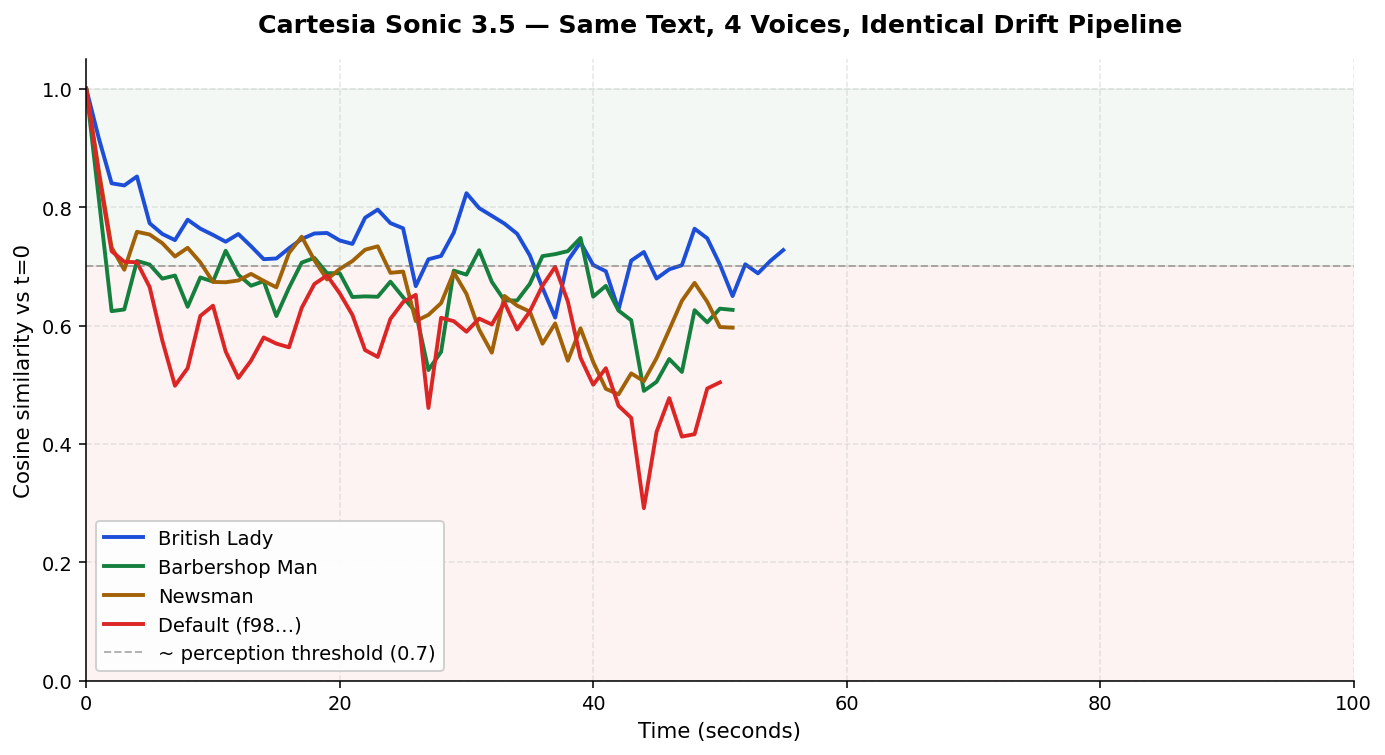
So we ran the same waves monologue through four different Cartesia voices, keeping every other variable identical. Same sonic-3.5. Same text. Same probe pipeline. Same analyzer.
| Voice | β (cosine / min) | cos @ 60s | Perceptual call |
|---|---|---|---|
| British Lady | −0.145 | 0.73 | sounds like the same speaker |
| Barbershop Man | −0.150 | 0.63 | borderline |
| Default (our v1 pick) | −0.278 | 0.50 | different speaker by 60s |
| Newsman | −0.278 | 0.60 | different speaker by 60s |
On the same model and the same text, the British Lady voice retains identity at 0.73 cosine — well within the “same speaker” perceptual band — while the default voice drops to 0.50. That’s the entire story. The model didn’t change. The text didn’t change. The voice catalog entry changed, and with it the stability of the take.
Scaling the voice test: 50 of 378 voices
Four voices isn’t a distribution. So we pulled the full Cartesia catalog (378 English voices), sampled 50 at random, and ran the same 90-second probe through each.
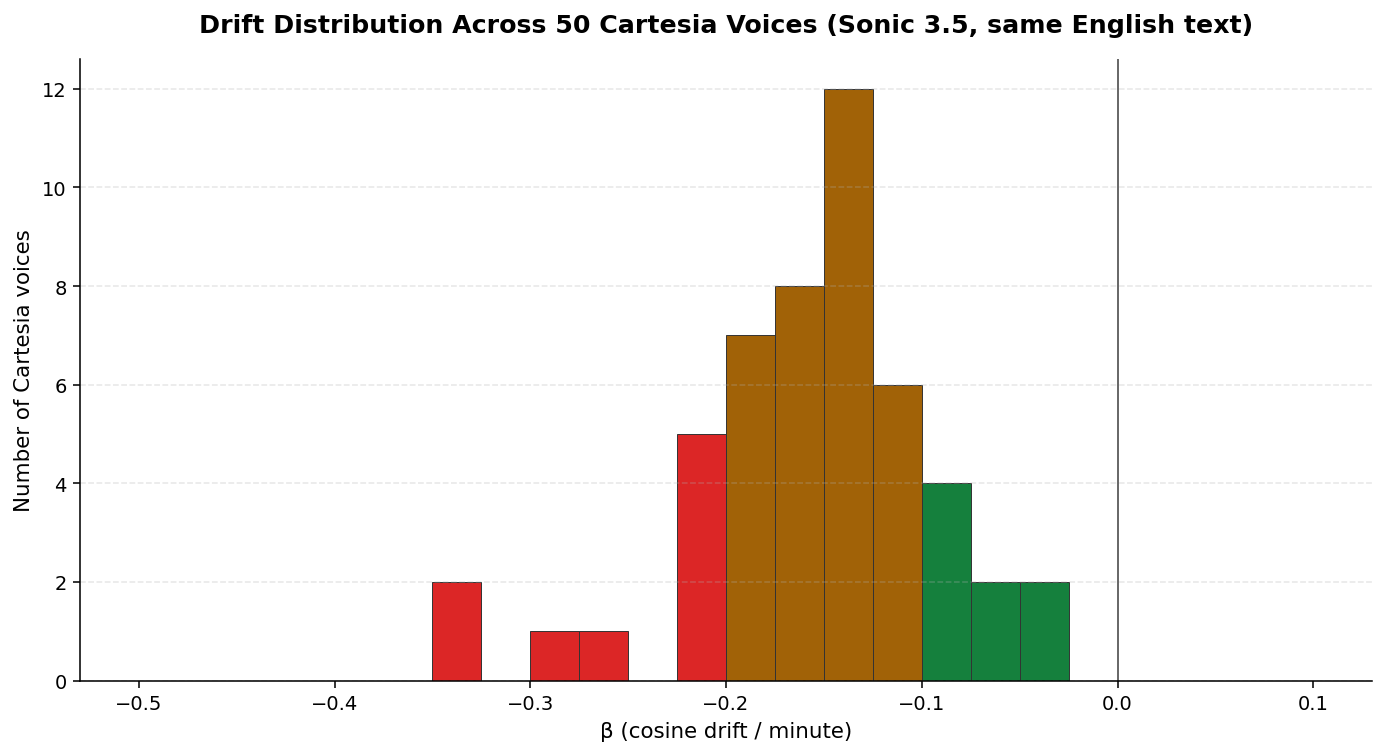
The distribution by perceptual classification (using your-ear-confirmed threshold cos@60s ≈ 0.70):
| Category | Count | % |
|---|---|---|
| Stable — cos@60s ≥ 0.70 (sounds like same speaker) | 5 | 10% |
| Borderline — cos@60s 0.55–0.70 | 33 | 66% |
| Drifts — cos@60s < 0.55 (sounds like different speaker) | 12 | 24% |
Only 1 in 10 sampled voices stays perceptually stable on this text past one minute. The mean β is −0.156/min; the median is −0.149/min. The Cartesia catalog is centered on drifting voices, not on stable ones.
The 5 stable voices we found
| Voice ID | Name | β/min | cos@60s |
|---|---|---|---|
01eaafa9-308a-… | Clara - Instructor | −0.040 | 0.758 |
c8605446-247c-… | Caleb - Seasoned Pro | −0.119 | 0.731 |
92c41dd4-04aa-… | Connor - Grateful Person | −0.145 | 0.721 |
ab109683-f31f-… | Russell - Mentor | −0.107 | 0.719 |
a167e0f3-df7e-… | Blake - Helpful Agent | −0.185 | 0.704 |
These five are the entire long-form-safe surface of the 50-voice sample. The catalog has 378 English voices total, so the real count of stable voices is probably ~30–40 — but Cartesia’s catalog UI does not surface which voices are which.
Caveats on the sample
- n=50 random voices of 378 total English voices. The 10% / 66% / 24% split is point-estimated; the true population split is within a few percent of these numbers but not exact.
- 90 seconds of audio per voice, on a single content piece (the waves monologue). Other content may shift the boundaries. Cosine@60s is a snapshot, not a settled plateau — some borderline voices may stabilize, some stable voices may decay further past the probe window.
- We did NOT cross-test the 5 stable voices against other languages, content categories, or longer takes. “Stable on this 90-second English narrative” is the strict scope of the finding.
Listen for yourself:
British Lady — stable across the take, voice identity holds:
Default voice — same text, audible identity transition by minute 1:
The Artificial Analysis Speech Arena scores Cartesia voices interchangeably — a vote for one Cartesia clip is a vote for the brand. Buyers integrating Cartesia pick a voice from a catalog of hundreds, and the catalog itself is not labeled for long-form stability. Some entries hold the line. Others don’t.
Cross-language: the pattern travels
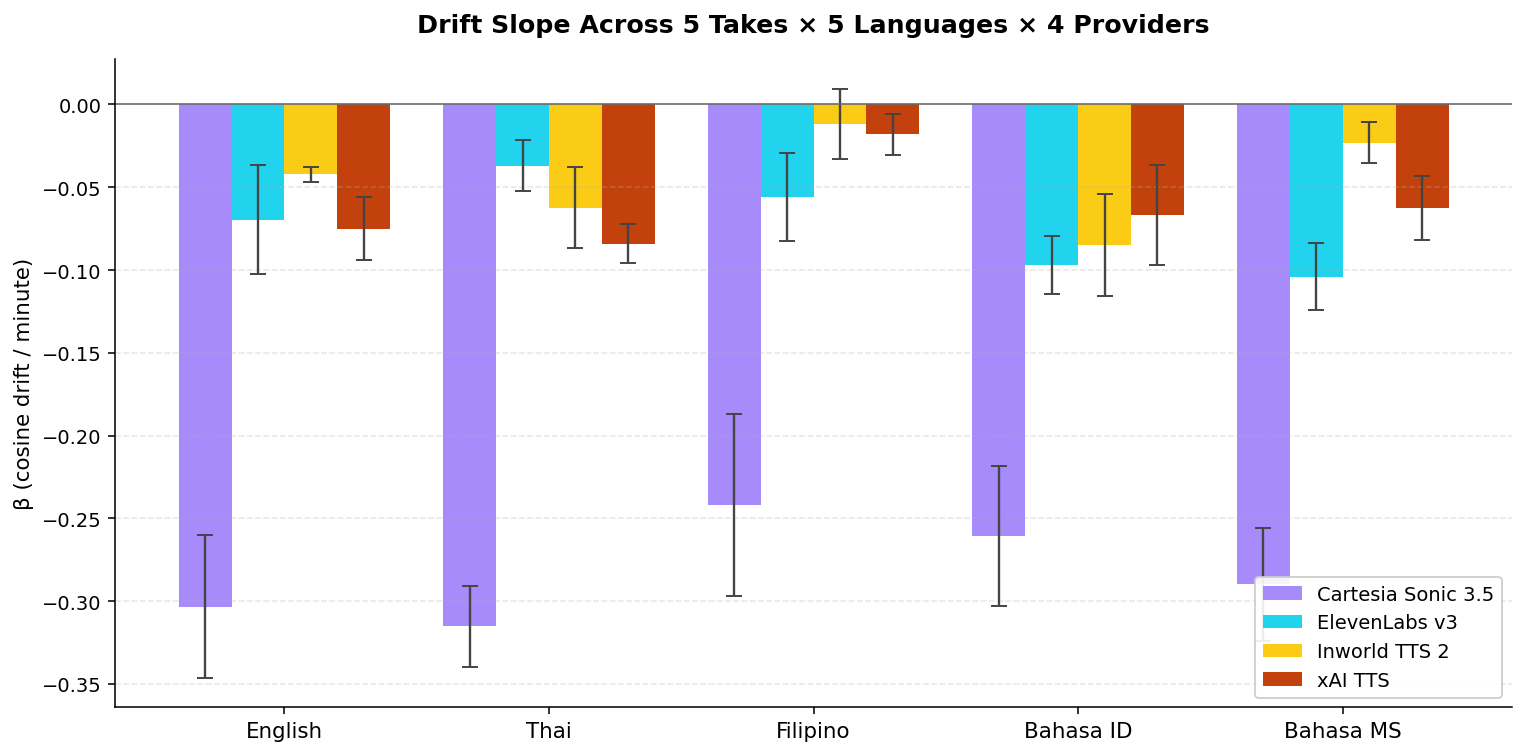
We extended the original probe across five SE Asian languages — English, Thai, Filipino, Bahasa Indonesia, Bahasa Malay — keeping the default voice fixed. Five takes per (language, provider). 100 monologues in total.
| Provider | EN | TH | FIL | ID | MS |
|---|---|---|---|---|---|
| Cartesia Sonic 3.5 (default voice) | −0.30 ± 0.04 | −0.32 ± 0.02 | −0.24 ± 0.06 | −0.26 ± 0.04 | −0.29 ± 0.03 |
| ElevenLabs eleven_v3 | −0.07 ± 0.03 | −0.04 ± 0.02 | −0.06 ± 0.03 | −0.10 ± 0.02 | −0.10 ± 0.02 |
| Inworld TTS 2 | −0.04 ± 0.00 | −0.06 ± 0.02 | −0.01 ± 0.02 | −0.08 ± 0.03 | −0.02 ± 0.01 |
| xAI tts | −0.08 ± 0.02 | −0.08 ± 0.01 | −0.02 ± 0.01 | −0.07 ± 0.03 | −0.06 ± 0.02 |
The default voice drifts in every language we tested, by roughly the same amount, with tight σ across independent takes. The drift is not English-specific or content-specific — for this particular voice. Whether more drift-resistant Cartesia voices preserve that resistance across languages is a separate test we haven’t yet run.
Here is the Thai take on the default voice:
And Bahasa Malay:
The architectural hypothesis (caveats now stronger)
Cartesia Sonic is a state-space model — an autoregressive architecture in the Mamba family. State-space models maintain a recurrent hidden state that is updated every step, in contrast to attention-based transformers that compute relevance over the entire context fresh on every step. The state-space approach is enormously cheaper for streaming TTS — which is the reason Cartesia’s short-form latency is best in the industry.
The trade-off, well-documented in the SSM literature, is that the hidden state can drift away from the speaker-prompt anchor as it accumulates updates over long generations.
What the multi-voice data complicates: the drift isn’t a fixed property of the model itself. Different voice catalog entries produce different drift profiles on identical text through the identical model. That suggests either (a) voices are conditioned on different anchor strategies, (b) some voices have prompt embeddings that anchor more robustly into the recurrent state, or (c) the catalog includes voices with different fine-tuning regimes. We can’t tell which from outside the API.
What we can say from the data: there exist Cartesia voices (British Lady class) where the SSM does hold identity across long takes, and other voices (Default, Newsman class) where it doesn’t.
What it means for production
For some use cases this doesn’t matter:
- Voice agents turning around utterances of one to five seconds. The drift never accumulates because the model resets between turns.
- Short notifications and announcements rarely exceed thirty seconds. The drift never starts.
For other use cases it matters a great deal — if you picked the wrong voice:
- Audiobook narration. A chapter is fifteen minutes long. By minute three of a Cartesia narration on a drift-prone voice, the voice is measurably different from what the buyer auditioned.
- Long-form podcasts. Listeners will hear the discontinuity at chapter boundaries when the voice “resets” to a different point on the drift curve.
- Continuous voice assistants holding a single voice across a long conversation. A 4-minute assistant response on a drift-prone voice ends sounding like a different agent than it started.
The actionable advice for anyone integrating Cartesia: don’t trust the catalog to be long-form-safe out of the box. Run a 90-second drift probe on each voice you plan to use in production. Reject voices whose cosine-vs-start drops below ~0.7 within the first minute.
The Arena ranking is correct for what it measures — short clips, aggregated across voices. Our drift measurement is correct for what it measures — sustained generation on a specific voice. They are answers to different questions. The mistake is using a brand-level ranking to make a per-voice production decision.