Semantic Was Supposed to Be the Smart One. It Lost.
OpenAI's Realtime API gives you two turn-detection modes. server_vad is the energy detector from the 1990s. semantic_vad is the word-aware classifier the docs recommend for natural conversation. We ran 158 trials against gpt-realtime-2 across both modes and seven stimulus types. server_vad with threshold 0.8 absorbs every quiet backchannel we threw at it. semantic_vad never absorbs anything. The recommended mode is worse, at every eagerness setting, in the only acoustic regime where the choice matters.
If you build a voice agent on OpenAI’s Realtime API, the very first decision you make is which turn-detection mode to use. The API gives you two: server_vad and semantic_vad. The first is an energy detector — listens to the volume of the user’s microphone and cancels the agent when it crosses a threshold. The second is a classifier — supposed to understand the actual words the user said and decide whether they’re taking their turn or just encouraging the agent to keep going.
OpenAI’s own docs describe semantic_vad as the upgrade for natural conversation. Community threads pass along the same advice: if your agent keeps cancelling on “uh huh,” switch to semantic_vad with eagerness: low. The pitch is intuitive — if the classifier can hear the actual word, surely it can tell “uh huh” from “wait, stop.”
We tested it. Listen to the same 1.7-second [under breath] mm hmm injected into the agent’s audio at two different VAD configurations, both running against gpt-realtime-2:
server_vad, threshold 0.8 — the energy detector
Agent runs to natural completion. The closed-mouth “mm hmm” never crossed the energy threshold. The backchannel is the small teal blip near the start.
semantic_vad, eagerness low — the word-aware classifier

Same audio. Same model. The classifier the docs recommend. Agent cuts off mid-thought; six seconds of silence after — the thirty-eight more seconds of moon-facts that never reached the listener.
That’s the head-to-head in one comparison: server VAD absorbs the backchannel and lets the agent finish. Semantic VAD — the one the documentation tells you to use when this exact thing keeps happening — cancels the response. We ran the same test across every eagerness setting semantic_vad exposes. Every one of them behaves like the clip you just heard.
What each mode is, in one paragraph each
server_vad (OpenAI docs). The kind of voice activity detector that’s been shipping since the 1990s. It measures the audio level on the user’s microphone channel and fires input_audio_buffer.speech_started when energy crosses a configurable threshold (0–1) for at least silence_duration_ms. It has no idea what was said — it can’t distinguish a hum, a cough, “stop,” or “uh huh” from each other. The only knob you have is the threshold: higher means quieter sounds are ignored. It’s dumb but predictable.
semantic_vad (OpenAI docs). A classifier that processes the actual audio content. From the docs: “Semantic VAD uses a semantic classifier to detect when the user has finished speaking, based on the words they have uttered. The classifier scores the input audio based on the probability that the user is done speaking.” It’s tuned with eagerness (low / medium / high / auto) — higher eagerness means the model commits to “user is done” faster; lower means it waits longer to be sure. This is the mode the docs and community threads recommend when backchannels are causing problems.
The marketing arc is intuitive: server VAD doesn’t know words, semantic VAD does, therefore semantic VAD should handle backchannels better. We built the matrix to test whether that’s true.
What we ran
A TypeScript harness opens a Realtime API session, configures the named turn-detection mode, seeds a prompt that produces about thirty seconds of speech (“Tell me three interesting facts about the Moon, in detail, in about thirty seconds”), waits until the agent starts speaking, and 800 milliseconds in, injects one of seven short audio clips into input_audio_buffer.append. We log every server event, save a stereo WAV of each trial (left: agent output; right: injected audio), and check whether the server fired input_audio_buffer.speech_started and cancelled the response.
| Model under test | gpt-realtime-2 (OpenAI Realtime GA, May 2026) |
| Server VAD configs | threshold 0.5 / 0.8 / 0.9 |
| Semantic VAD configs | eagerness low / medium / high / auto |
| Stimuli | ”uh huh”, “okay”, “yeah”, full-voice “mm hmm”, [under breath] “mm hmm”, 400 ms cough, “Wait, stop” |
| Backchannel audio sources | OpenAI gpt-4o-mini-tts (full voice) + ElevenLabs eleven_v3 with [softly] / [under breath] audio tags |
| Cough source | Freesound “Cough (3)” by OwlStorm, CC0, 400 ms, 24 kHz |
| Injection point | 800 ms into the agent’s audio stream |
| Cancellation criterion | server fires input_audio_buffer.speech_started AND response.done returns status: cancelled |
| Trial count | 158 trials total (84 OpenAI-TTS source + 74 Eleven-v3 source) |
The head-to-head
![Head-to-head heatmap: stimulus type × VAD config. Server VAD with threshold 0.8 and 0.9 absorbs the [under breath] mm hmm. Every other backchannel cancels at every config. Cough absorbs everywhere. Real interrupt cancels everywhere.](/blog-clips/the-backchannel-trap/head-to-head.png)
One image, the entire matrix. Read it across, not down. Each row is a stimulus we injected. Each column is a VAD configuration. Purple cells are responses that got cancelled. Teal cells are responses that ran to completion.
Three things to notice.
- The top four rows are uniformly purple. Any backchannel loud enough to be heard as a word —
"uh huh","okay","yeah", a full-voice"mm hmm"— cancels the agent at every VAD configuration we tested. Server, semantic, every threshold, every eagerness. No difference. - The cough row is uniformly teal. Both VAD families correctly absorb a 400 ms transient burst. The cough is a non-issue across the board.
- The two teal cells in the
[under breath] mm hmmrow are the entire reason this article exists. That row is the only place server_vad and semantic_vad disagree in our matrix, and server_vad wins both cells. Threshold 0.8 and 0.9 are quiet enough that the breath-only “mm hmm” doesn’t cross the energy bar. Everysemantic_vadconfiguration — low, medium, high, auto — cancels the response.
There is no acoustic regime in our 158 trials where semantic_vad outperforms server_vad. They tie on loud backchannels (both fail). They tie on the cough (both succeed). They tie on the real interrupt (both succeed). Then on the one stimulus where the choice of mode actually changes the outcome, semantic_vad loses at every setting it exposes.
Listen to the boundary
The same [under breath] mm hmm we used in the lead, played through every VAD configuration we tested. Same audio. Different mode and setting. Same listener experience would feel very different across these five.
server_vad, threshold 0.8 — absorbed
52 seconds. Agent runs through the moon prompt to completion.
server_vad, threshold 0.9 — absorbed
Also 52 seconds. Higher threshold, same outcome — the breath-only backchannel never crossed the energy bar.
semantic_vad, eagerness low — cancelled
Agent cuts off within a second of the backchannel. Six seconds of silence after. The classifier “saw” the same audio that server_vad just absorbed.
semantic_vad, eagerness medium — cancelled
semantic_vad, eagerness high — cancelled
semantic_vad, eagerness auto — cancelled
Four eagerness settings. Four cancellations. The mode that’s marketed as “smarter than energy detection” cancels on audio quiet enough that the energy detector lets it pass.
”But the classifier sees the words” — yes, and it ignores them
semantic_vad is documented as scoring the probability that the user is done speaking based on the words they uttered. So the obvious question: does the classifier actually behave differently from energy detection, or does it just emit the same binary “cancel” decision through a more expensive path?
The latency data is the tell.
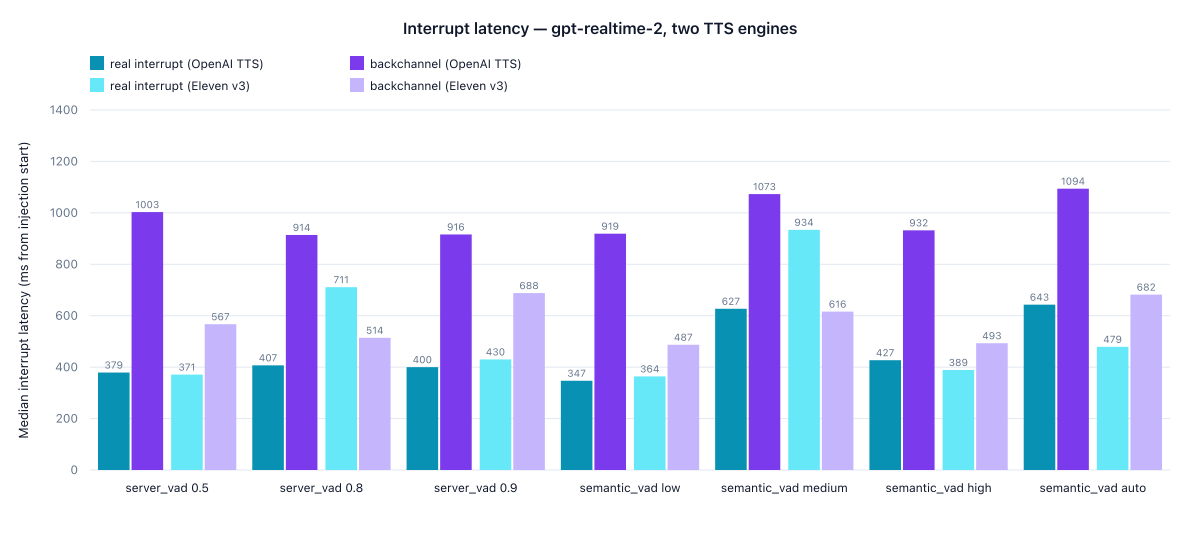
A real interrupt ("Wait, stop") trips the cancellation in 350-430 milliseconds, every config. A backchannel trips it in 500-1100 milliseconds. The cancellation is consistently slower for backchannels than for real interrupts — between 1.5× and 3× slower. The classifier hesitates. It sees the difference.
But the binary cancel signal that comes out the other end is identical. The classifier processes the audio, internally scores it as somewhere between “definitely a turn-take” and “probably a backchannel,” and then commits to the same response.done status=cancelled either way. The microsecond of indecision is the only place the word-level smarts leak through, and nothing in the API surfaces that. You can’t read the probability, you can’t act on it, you can’t tell the model to delay slightly longer when uncertain. It hesitates, then cancels, and you see exactly the same speech_started event you’d see from server_vad.
The marketing claim — that semantic_vad is content-aware — is technically true. The functional claim — that semantic_vad is the fix for backchannel cancellation — is not.
The cough — testing the stimulus everyone tests
There’s an established voice-agent stress test: fire a cough into the agent’s audio and see whether it spuriously interrupts. We wrote about this last month — four production stacks, none of them broke. We re-ran it against the same gpt-realtime-2 model, same 400-millisecond cough, across all seven VAD configurations.
server_vad, threshold 0.8
Fifty-one seconds of agent talking moon facts. The cough is the tiny teal blip on the right channel near the start.
semantic_vad, eagerness low
Forty-three seconds, same outcome. The classifier doesn’t trigger on a 400 ms transient either — both VAD families correctly identify the cough as non-speech.
Cough trials across the matrix: zero out of fourteen cancelled. Across every VAD config in both families. The thing that every voice-agent demo stress-tests is the thing both VAD modes already handle. The thing nobody tests — a polite “uh huh” — is the thing that breaks the response every time.
And what a real interrupt sounds like
To rule out “these VADs don’t work at all” — they do work, they just work on the wrong axis. Same model, same injection point, same harness. Instead of a backchannel we injected the phrase “Wait, stop.”
server_vad threshold 0.8 — cancels correctly
semantic_vad eagerness low — cancels correctly
Both modes hear “Wait, stop” and fire speech_started within 350–430 ms. The cancellation is the right answer here — the user actually is taking their turn. Both modes get this case right, every trial.
The problem isn’t that the VADs don’t fire when they should. The problem is that they also fire when they shouldn’t — for backchannels — and the user gets cut off mid-sentence even when they were politely encouraging the agent to keep going.
The recommendation
For gpt-realtime-2 under the conditions in our matrix:
- Default:
server_vadwiththreshold: 0.8. It absorbs quiet backchannels (the only case where the two modes disagree), it ties everywhere else, and it’s tunable. If you can rely on your users speaking at conversational volume — or below — this is the best mode the API offers. - Bump to
threshold: 0.9if your interrupts are louder than typical conversation. Same backchannel-absorbing behavior, fewer real-interrupt false positives. - Don’t pick
semantic_vadbased on the marketing. The pitch is that it’s smarter; the measurement says it isn’t. There’s no eagerness setting where it outperforms tunedserver_vad, and at every setting we tested it cancels on backchannels server_vad would have absorbed. - Neither mode is good enough for production voice agents serving everyday conversational backchannels. If your agent will be in 1:1 dialogue with users who say “uh huh” at conversational volume — the most common acoustic regime in voice agents — both modes cancel the agent every time. The fix isn’t a different VAD; it’s a turn-detection model that’s trained on the backchannel-vs-turn-take distinction, which neither of OpenAI’s modes is.